`
| |
|
Tuesday, March 19th, 2013
It’s easy to speak of test-driven development as if it were a single method, but there are several ways to approach it. In my experience, different approaches lead to quite different solutions.
In this hands-on workshop, with the help of some concrete examples, I’ll demonstrate the different styles and more importantly what goes into the moment of decision when a test is written? And why TDDers make certain choices. The objective of the session is not to decide which approach is best, rather to highlight various different approaches/styles of practicing test-driven development.
By the end of this session, you will understand how TTDers break down a problem before trying to solve it. Also you’ll be exposed to various strategies or techniques used by TDDers to help them write the first few tests.
Posted in Agile, Design, Programming, Testing | No Comments »
Tuesday, March 19th, 2013
Recently at the Agile India 2013 Conference I ran an introductory workshop on Behavior Driven Development. This workshop offered a comprehensive, hands-on introduction to behavior driven development via an interactive-demo.
Over the past decade, eXtreme Programming practices like Test-Driven Development (TDD) and Behaviour Driven Development (BDD) have fundamentally changed software development processes and inherently how engineers work. Practitioners claim that it has helped them significantly improve their collaboration with business, development speed, design & code quality and responsiveness to changing requirements. Software professionals across the board, from Internet startups to medical device companies to space research organizations, today have embraced these practices.
This workshop explores the foundations of TDD & BDD with the help of various patterns, strategies, tools and techniques.
Posted in Agile, Continuous Deployment, Design, Programming | No Comments »
Tuesday, March 19th, 2013
As more and more companies are moving to the Cloud, they want their latest, greatest software features to be available to their users as quickly as they are built. However there are several issues blocking them from moving ahead.
One key issue is the massive amount of time it takes for someone to certify that the new feature is indeed working as expected and also to assure that the rest of the features will continuing to work. In spite of this long waiting cycle, we still cannot assure that our software will not have any issues. In fact, many times our assumptions about the user’s needs or behavior might itself be wrong. But this long testing cycle only helps us validate that our assumptions works as assumed.
How can we break out of this rut & get thin slices of our features in front of our users to validate our assumptions early?
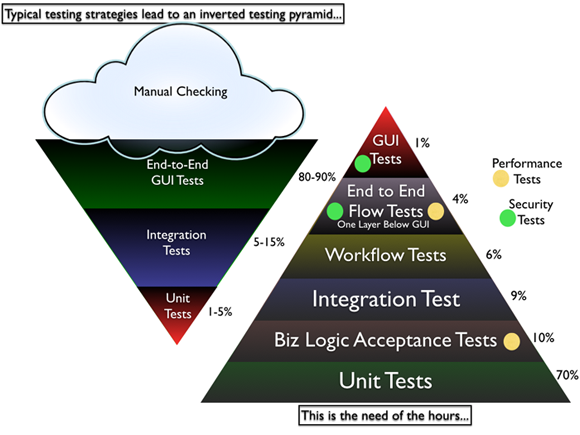
Most software organizations today suffer from what I call, the “Inverted Testing Pyramid” problem. They spend maximum time and effort manually checking software. Some invest in automation, but mostly building slow, complex, fragile end-to-end GUI test. Very little effort is spent on building a solid foundation of unit & acceptance tests.
This over-investment in end-to-end tests is a slippery slope. Once you start on this path, you end up investing even more time & effort on testing which gives you diminishing returns.
In this session Naresh Jain will explain the key misconceptions that has lead to the inverted testing pyramid approach being massively adopted, main drawbacks of this approach and how to turn your organization around to get the right testing pyramid.
Posted in Agile, Continuous Deployment, Deployment, Testing | No Comments »
Sunday, July 8th, 2012
| A |
Acceptance Criteria/Test, Automation, A/B Testing, Adaptive Planning, Appreciative inquiry |
| B |
Backlog, Business Value, Burndown, Big Visible Charts, Behavior Driven Development, Bugs, Build Monkey, Big Design Up Front (BDUF) |
| C |
Continuous Integration, Continuous Deployment, Continuous Improvement, Celebration, Capacity Planning, Code Smells, Customer Development, Customer Collaboration, Code Coverage, Cyclomatic Complexity, Cycle Time, Collective Ownership, Cross functional Team, C3 (Complexity, Coverage and Churn), Critical Chain |
| D |
Definition of Done (DoD)/Doneness Criteria, Done Done, Daily Scrum, Deliverables, Dojos, Drum Buffer Rope |
| E |
Epic, Evolutionary Design, Energized Work, Exploratory Testing |
| F |
Flow, Fail-Fast, Feature Teams, Five Whys |
| G |
Grooming (Backlog) Meeting, Gemba |
| H |
Hungover Story |
| I |
Impediment, Iteration, Inspect and Adapt, Informative Workspace, Information radiator, Immunization test, IKIWISI (I’ll Know It When I See It) |
| J |
Just-in-time |
| K |
Kanban, Kaizen, Knowledge Workers |
| L |
Last responsible moment, Lead time, Lean Thinking |
| M |
Minimum Viable Product (MVP), Minimum Marketable Features, Mock Objects, Mistake Proofing, MOSCOW Priority, Mindfulness, Muda |
| N |
Non-functional Requirements, Non-value add |
| O |
Onsite customer, Opportunity Backlog, Organizational Transformation, Osmotic Communication |
| P |
Pivot, Product Discovery, Product Owner, Pair Programming, Planning Game, Potentially shippable product, Pull-based-planning, Predictability Paradox |
| Q |
Quality First, Queuing theory |
| R |
Refactoring, Retrospective, Reviews, Release Roadmap, Risk log, Root cause analysis |
| S |
Simplicity, Sprint, Story Points, Standup Meeting, Scrum Master, Sprint Backlog, Self-Organized Teams, Story Map, Sashimi, Sustainable pace, Set-based development, Service time, Spike, Stakeholder, Stop-the-line, Sprint Termination, Single Click Deploy, Systems Thinking, Single Minute Setup, Safe Fail Experimentation |
| T |
Technical Debt, Test Driven Development, Ten minute build, Theme, Tracer bullet, Task Board, Theory of Constraints, Throughput, Timeboxing, Testing Pyramid, Three-Sixty Review |
| U |
User Story, Unit Tests, Ubiquitous Language, User Centered Design |
| V |
Velocity, Value Stream Mapping, Vision Statement, Vanity metrics, Voice of the Customer, Visual controls |
| W |
Work in Progress (WIP), Whole Team, Working Software, War Room, Waste Elimination |
| X |
xUnit |
| Y |
YAGNI (You Aren’t Gonna Need It) |
| Z |
Zero Downtime Deployment, Zen Mind |
Posted in Agile | No Comments »
Friday, June 15th, 2012
This is an introductory presentation on the essence of Being Agile vs. Following Agile. And why being Agile is important? I’ve also tried to show an evolution of Agile methods over the last 11 years and the future of Agile. Also take a sneak preview into what challenges an organizations may face when trying to be agile?
Posted in Agile, Lean Startup, Organizational | No Comments »
Friday, May 18th, 2012
You might think Definition of Done (DoD) is a brilliant idea from the Agile world…but the dirty little secret is… its just a hand-over from the waterfall era.
While the DoD thought-process is helpful, it can lead to certain unwanted behavior in your team. For example:
- DoD usually ends up being a measure of output, but rarely it focuses on outcome.
- In some teams, I’ve seen it disrupt true collaboration and instead encourage more of a contractual and “cover my @ss” mentality.
- DoD creates a false-sense/illusion of doneness. Unless you have real data showing users actually benefiting and using the feature/story, how can we say its done?
- I’ve also seen teams gold-plating stuff in the name of DoD. DoD encourages a all-or-nothing approach. Teams are forced to build fully sophisticated features/stories. We might not even be sure if those features/stories are really required or not.
- It get harder to practice iterative & incremental approach to develop features. DoD does not encourage experimenting with different sophistication levels of a feature.
I would much rather prefer the team members to truly collaborate on an-ongoing basis. Build features in an iterative and incremental fashion. Strongly focus on Simplicity (maximizing the amount of work NOT done.) IME Continuous Deployment is a great practice to drive some of this behavior.
More recent blog on this: Done with Definition of Done or shoud I say Definition of Done Considered Harmful
Posted in Agile, Organizational | 4 Comments »
Tuesday, November 1st, 2011
“Release Early, Release Often” is a proven mantra, but what happens when you push this practice to it’s limits? .i.e. deploying latest code changes to the production servers every time a developer checks-in code?
At Industrial Logic, developers are deploying code dozens of times a day, rapidly responding to their customers and reducing their “code inventory”.
This talk will demonstrate our approach, deployment architecture, tools and culture needed for CD and how at Industrial Logic, we gradually got there.
Process/Mechanics
This will be a 60 mins interactive talk with a demo. Also has a small group activity as an icebreaker.
Key takeaway: When we started about 2 years ago, it felt like it was a huge step to achieve CD. Almost a all or nothing. Over the next 6 months we were able to break down the problem and achieve CD in baby steps. I think that approach we took to CD is a key take away from this session.
Talk Outline
- Context Setting: Need for Continuous Integration (3 mins)
- Next steps to CI (2 mins)
- Intro to Continuous Deployment (5 mins)
- Demo of CD at Freeset (for Content Delivery on Web) (10 mins) – a quick, live walk thru of how the deployment and servers are set up
- Benefits of CD (5 mins)
- Demo of CD for Industrial Logic’s eLearning (15 mins) – a detailed walk thru of our evolution and live demo of the steps that take place during our CD process
- Zero Downtime deployment (10 mins)
- CD’s Impact on Team Culture (5 mins)
- Q&A (5 mins)
Target Audience
- CTO
- Architect
- Tech Lead
- Developers
- Operations
Context
Industrial Logic’s eLearning context? number of changes, developers, customers , etc…?
Industrial Logic’s eLearning has rich multi-media interactive content delivered over the web. Our eLearning modules (called Albums) has pictures & text, videos, quizes, programming exercises (labs) in 5 different programming languages, packing system to validate & produce the labs, plugins for different IDEs on different platforms to record programming sessions, analysis engine to score student’s lab work in different languages, commenting system, reporting system to generate different kind of student reports, etc.
We have 2 kinds of changes, eLearning platform changes (requires updating code or configuration) or content changes (either code or any other multi-media changes.) This is managed by 5 distributed contributors.
On an average we’ve seen about 12 check-ins per day.
Our customers are developers, managers and L&D teams from companies like Google, GE Energy, HP, EMC, Philips, and many other fortune 100 companies. Our customers have very high expectations from our side. We have to demonstrate what we preach.
Learning outcomes
- General Architectural considerations for CD
- Tools and Cultural change required to embrace CD
- How to achieve Zero-downtime deploys (including databases)
- How to slice work (stories) such that something is deployable and usable very early on
- How to build different visibility levels such that new/experimental features are only visible to subset of users
- What Delivery tests do
- You should walk away with some good ideas of how your company can practice CD
Slides from Previous Talks
Posted in Agile, Continuous Deployment, Deployment, Lean Startup, Product Development, Testing, Tools | No Comments »
Sunday, March 6th, 2011
Recently TV tweeted saying:
Is “measure twice, cut once” an #agile value? Why shouldn’t it be – it is more fundamental than agile.
To which I responded saying:
“measure twice, cut once” makes sense when cost of a mistake & rework is huge. In software that’s not the case if done in small, safe steps. A feedback centric method like #agile can help reduce the cost of rework. Helping you #FailFast and create opportunities for #SafeFailExperiements. (Extremely important for innovation.)
To step back a little, the proverb “measure twice and cut once” in carpentry literally mean:
“One should double-check one’s measurements for accuracy before cutting a piece of wood; otherwise it may be necessary to cut again, wasting time and material.”
Speaking more figuratively it means “Plan and prepare in a careful, thorough manner before taking action.”
Unfortunately many software teams literally take this advice as
“Let’s spend a few solid months carefully planning, estimating and designing software upfront, so we can avoid rework and last minute surprise.”
However after doing all that, they realize it was not worth it. Best case they delivered something useful to end users with about 40% rework. Worst case they never delivered or delivered something buggy that does not meet user’s needs. But what about the opportunity cost?
Why does this happen?
Humphrey’s law says: “Users will not know exactly what they want until they see it (may be not even then).”
So how can we plan (measure twice) when its not clear what exactly our users want (even if we can pretend that we understand our user’s needs)?
How can we plan for uncertainty?
IMHO you can’t plan for uncertainty. You respond to uncertainty by inspecting and adapting. You learn by deliberately conducting many safe-fail experiments.
What is Safe-Fail Experimentation?
Safe-fail experimentation is a learning and problem solving technique which emphasizes on conducting many simultaneous, small, controlled experiments with small variations. Since these are small controlled experiments, failure is an expected & acceptable outcome.
In the software world, spiking, low-fi-prototypes, set-based design, continuous deployment, A/B Testing, etc. are all forms of safe-fail experiments.
Generally we like to start with something really small (but end-to-end) and rapidly build on it using user feedback and personal experience. Embracing Simplicity (“maximizing the amount of work not done”) is critical as well. You frequently cut small pieces, integrate the whole and see if its aligned with user’s needs. If not, the cost of rework is very small. Embrace small #SafeFail experiments to really innovate.
Or as Kerry says:
“Perhaps the fundamental point is that in software development the best way of measuring is to cut.”
Also strongly recommend you read the Basic principles of safe-fail experimentation.
Posted in Agile, Continuous Deployment, Planning | No Comments »
Tuesday, February 1st, 2011
As more and more companies are moving to the Cloud, they want their latest, greatest software features to be available to their users as quickly as they are built. However there are several issues blocking them from moving ahead.
One key issue is the massive amount of time it takes for someone to certify that the new feature is indeed working as expected and also to assure that the rest of the features will continuing to work. In spite of this long waiting cycle, we still cannot assure that our software will not have any issues. In fact, many times our assumptions about the user’s needs or behavior might itself be wrong. But this long testing cycle only helps us validate that our assumptions works as assumed.
How can we break out of this rut & get thin slices of our features in front of our users to validate our assumptions early?
Most software organizations today suffer from what I call, the “Inverted Testing Pyramid” problem. They spend maximum time and effort manually checking software. Some invest in automation, but mostly building slow, complex, fragile end-to-end GUI test. Very little effort is spent on building a solid foundation of unit & acceptance tests.
This over-investment in end-to-end tests is a slippery slope. Once you start on this path, you end up investing even more time & effort on testing which gives you diminishing returns.
They end up with majority (80-90%) of their tests being end-to-end GUI tests. Some effort is spent on writing so-called “Integration test” (typically 5-15%.) Resulting in a shocking 1-5% of their tests being unit/micro tests.
Why is this a problem?
- The base of the pyramid is constructed from end-to-end GUI test, which are famous for their fragility and complexity. A small pixel change in the location of a UI component can result in test failure. GUI tests are also very time-sensitive, sometimes resulting in random failure (false-negative.)
- To make matters worst, most teams struggle automating their end-to-end tests early on, which results in huge amount of time spent in manual regression testing. Its quite common to find test teams struggling to catch up with development. This lag causes many other hard-development problems.
- Number of end-to-end tests required to get a good coverage is much higher and more complex than the number of unit tests + selected end-to-end tests required. (BEWARE: Don’t be Seduced by Code Coverage Numbers)

- Maintain a large number of end-to-end tests is quite a nightmare for teams. Following are some core issues with end-to-end tests:
- It requires deep domain knowledge and high technical skills to write quality end-to-end tests.
- They take a lot of time to execute.
- They are relatively resource intensive.
- Testing negative paths in end-to-end tests is very difficult (or impossible) compared to lower level tests.
- When an end-to-end test fails, we don’t get pin-pointed feedback about what went wrong.
- They are more tightly coupled with the environment and have external dependencies, hence fragile. Slight changes to the environment can cause the tests to fail. (false-negative.)
- From a refactoring point of view, they don’t give the same comfort feeling to developers as unit tests can give.
Again don’t get me wrong. I’m not suggesting end-to-end integration tests are a scam. I certainly think they have a place and time.
Imagine, an automobile company building an automobile without testing/checking the bolts, nuts all the way up to the engine, transmission, breaks, etc. And then just assembling the whole thing somehow and asking you to drive it. Would you test drive that automobile? But you will see many software companies using this approach to building software.
What I propose and help many organizations achieve is the right balance of end-to-end tests, acceptance tests and unit tests. I call this “Inverting the Testing Pyramid.” [Inspired by Jonathan Wilson’s book called Inverting The Pyramid: The History Of Football Tactics].
In a later blog post I can quickly highlight various tactics used to invert the pyramid.
Update: I recently came across Alister Scott’s blog on Introducing the software testing ice-cream cone (anti-pattern). Strongly suggest you read it.
Posted in Agile, Design, Testing | 14 Comments »
|